Using Lambda Layers with AWS CDK in Python
Using Lambda layers with AWS CDK in Python to handle dependencies and share code between lambda functions
On this page
While we created some simple lambda functions in a previous post, but in most cases, you will need to use some external libraries or dependencies in your lambda functions.
E.g., let’s modify our cdk_app/lambda/index.file to use the requests library:
# filename: cdk_app/lambda/index.py
import requests
def handler(event, context):
response = requests.get("https://jsonplaceholder.typicode.com/todos/1")
return {
"statusCode": 200,
"body": response.json()
}We put a requirements.txt file in the same directory as our index.py file with the following contents:
# filename: cdk_app/lambda/requirements.txt
requestsThen we can create a lambda function using this code as follows:
# filename: cdk_app/lambda_stack.py
from aws_cdk import (
Stack,
aws_lambda as _lambda,
)
from constructs import Construct
class LambdaStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
my_lambda = _lambda.Function(
self,
id="MyLambda",
runtime=_lambda.Runtime.PYTHON_3_10,
handler="index.handler",
code=_lambda.Code.from_asset("cdk_app/lambda"),
)After deploying the stack if you try to invoke the lambda function, you will get an error:
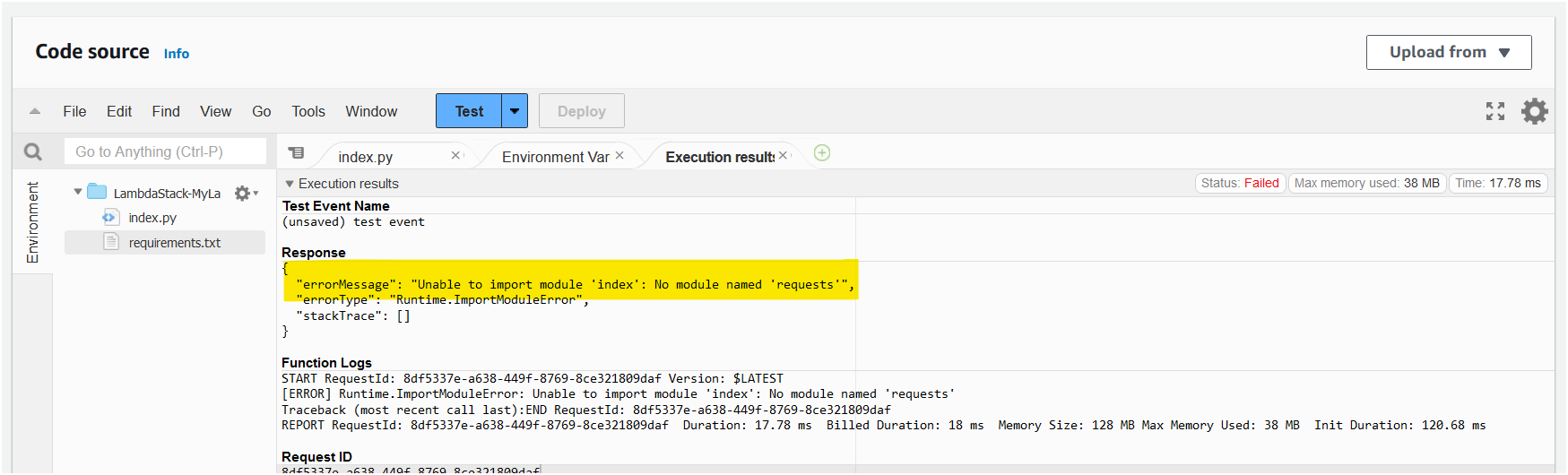
This is because by default, the lambda function does not have the requests library installed. To fix this, we need to create a lambda layer that contains the requests library and then add that layer to our lambda function.
When to use lambda layers
Lambda layers are useful in the following scenarios:
- Handle dependencies: If you need to use some external libraries or dependencies in your lambda function, you can put those dependencies in a lambda layer and then add that layer to your lambda function.
- Reuse code between lambda functions: If you have some common code that you want to use in multiple lambda functions, you can put that code in a lambda layer and then add that layer to all the lambda functions that need to use that code.
Create a lambda layer in AWS CDK using Python to handle dependencies
Essentially, handling dependencies means we have to download the dependencies and put them in a folder. Then we need to zip that folder and upload it to AWS.
We will create a function within our stack that will do this work for us, and then import that layer into our lambda function.
# filename: cdk_app/lambda_stack.py
from aws_cdk import (
Stack,
aws_lambda as _lambda,
)
from constructs import Construct
import os, subprocess # 👈🏽 needed to download dependencies
class LambdaStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
my_lambda = _lambda.Function(
self,
id="MyLambda",
runtime=_lambda.Runtime.PYTHON_3_10,
handler="index.handler",
code=_lambda.Code.from_asset("cdk_app/lambda"),
layers=[self.create_dependencies_layer(self.stack_name, "lambda/index")],
)
def create_dependencies_layer(self, project_name, function_name: str) -> _lambda.LayerVersion:
requirements_file = "cdk_app/lambda/requirements.txt" # 👈🏽 point to requirements.txt
output_dir = f".build/app" # 👈🏽 a temporary directory to store the dependencies
if not os.environ.get("SKIP_PIP"):
# 👇🏽 download the dependencies and store them in the output_dir
subprocess.check_call(f"pip install -r {requirements_file} -t {output_dir}/python".split())
layer_id = f"{project_name}-{function_name}-dependencies" # 👈🏽 a unique id for the layer
layer_code = _lambda.Code.from_asset(output_dir) # 👈🏽 import the dependencies / code
my_layer = _lambda.LayerVersion(
self,
layer_id,
code=layer_code,
)
return my_layerLet’s go through the code above:
import os, subprocess # 👈🏽 needed to download dependenciesWe imported the os and subprocess modules. We will use these modules to download the dependencies and store them in a temporary directory.
my_lambda = _lambda.Function(
self,
id="MyLambda",
runtime=_lambda.Runtime.PYTHON_3_10,
handler="index.handler",
code=_lambda.Code.from_asset("cdk_app/lambda"),
layers=[self.create_dependencies_layer(self.stack_name, "lambda/index")],
)Here, we defined the layers which is to be passed as a list. We are calling the create_dependencies_layer function to create the layer.
def create_dependencies_layer(self, project_name, function_name: str) -> _lambda.LayerVersion:
requirements_file = "cdk_app/lambda/requirements.txt" # 👈🏽 point to requirements.txt
output_dir = f".build/app" # 👈🏽 a temporary directory to store the dependencies
if not os.environ.get("SKIP_PIP"):
# 👇🏽 download the dependencies and store them in the output_dir
subprocess.check_call(f"pip install -r {requirements_file} -t {output_dir}/python".split())
layer_id = f"{project_name}-{function_name}-dependencies" # 👈🏽 a unique id for the layer
layer_code = _lambda.Code.from_asset(output_dir) # 👈🏽 import the dependencies / code
my_layer = _lambda.LayerVersion(
self,
layer_id,
code=layer_code,
)
return my_layerHere, we are creating the create_dependencies_layer function. This functions runs the following steps:
- It defines the
requirements_filevariable which points to therequirements.txtfile. - It defines the
output_dirvariable which points to a temporary directory where we will store the dependencies. - It uses
subprocessto run commands to downloads the dependencies and stores them in theoutput_dirdirectory. - It defines the
layer_idvariable which is a unique id for the layer. - It defines the
layer_codevariable which points to theoutput_dirdirectory. - It creates the
my_layervariable which is an instance of theLayerVersionconstruct. - It returns the
my_layervariable.
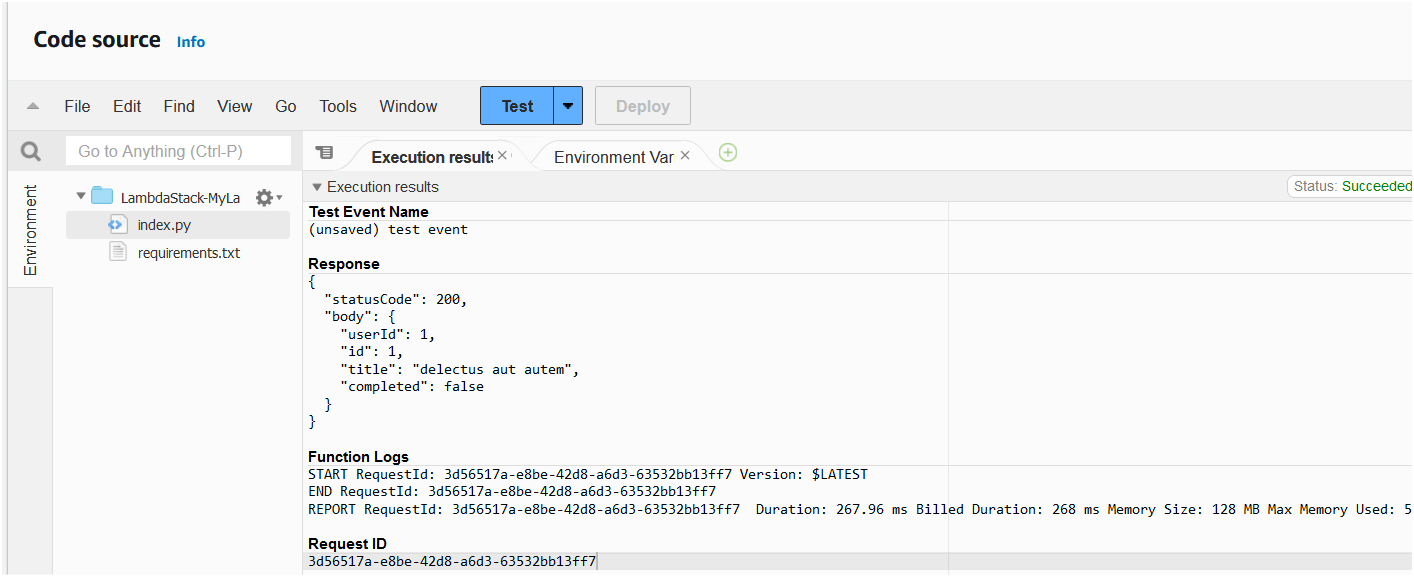
Now if you run cdk deploy, you will see that the lambda function is created successfully and you can invoke it successfully as well.
Reuse code between lambda functions
Another major use case is when you write some code that you want to reuse between multiple lambda functions. E.g. some utility function or helper function that you want to use in multiple lambda functions.
Similar to the previous example, we can create a layer by importing the code and then add that layer to our lambda functions.
Let’s create a helpers.py file in the cdk_app/utils directory with the following contents:
# filename: cdk_app/utils/helpers.py
def hello_world():
return "Hello World"Now we can create a layer using this code as follows:
# filename: cdk_app/lambda_stack.py
from aws_cdk import (
Stack,
aws_lambda as _lambda,
)
from constructs import Construct
class LambdaStack(Stack):
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
my_layer = _lambda.LayerVersion(
self,
"MyLayer",
code=_lambda.Code.from_asset("cdk_app/utils"),
)
my_lambda = _lambda.Function(
self,
id="MyLambda",
runtime=_lambda.Runtime.PYTHON_3_10,
handler="index.handler",
code=_lambda.Code.from_asset("cdk_app/lambda"),
layers=[my_layer],
)Now we can use the hello_world function in our lambda function as follows:
# filename: cdk_app/lambda/index.py
from utils.helpers import hello_world # 👈🏽 import the helper function
def handler(event, context):
return {
"statusCode": 200,
"body": hello_world() # 👈🏽 use the helper function
}This is a very simple example, but you can imagine that you can put a lot of code in the helpers.py file and then use that code in multiple lambda functions.
Conclusion
While layers are a very useful feature of lambda functions, they are not a silver bullet. You should use them wisely and only when needed. If you have a lot of code in your lambda function, you should consider using a different approach such as using a container image instead of a lambda function.
Need help?
Start a discussion on GitHub if you’ve got questions or improvements. Open discussions →