CDK Output: How to Output data from a stack
Explanation of concept of Outputs, how to use them to share data to other stacks
On this page
Previously, we learnt how to create multiple stacks. For most applications that you would build using CDK, you would need to share data between the stacks. For example, you might want to create an S3 bucket in one stack and then a Lambda function in another stack that uses that S3 bucket.
In this case, you would need to share the name of the S3 bucket between the stacks. This is where Outputs come in.
What are Outputs?
In AWS CloudFormation (which the CDK leverages under the hood), Outputs are a way to export specific values from a stack. These values can be anything: an S3 bucket name, a database connection string, or even a computed value.
Outputs are especially useful when:
- Linking Multiple Stacks: They allow one stack to use a resource from another stack.
- External Usage: When you want to use a specific value from your cloud infrastructure in an external system or application.
How to create an Output in CDK?
To create an Output in CDK, you need to use the CfnOutput class. This class is available in the aws_cdk module.
Create a new file called cdk_app/s3_stack.py and add the following code to it:
# cdk_app/s3_stack.py
from aws_cdk import (
Stack,
aws_s3 as s3,
RemovalPolicy,
)
from aws_cdk import CfnOutput # 👈🏽 Import the CfnOutput class
from constructs import Construct
class S3Stack(Stack):
BUCKET_ID = "MyS3Bucket"
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
myBucket = s3.Bucket(self, id=self.BUCKET_ID, removal_policy=RemovalPolicy.DESTROY)
# 👇🏽 Output the bucket ARN
CfnOutput(self, id="S3BucketARN", value=myBucket.bucket_arn, export_name="MyS3BucketARN")In the above example, we are creating an S3 bucket and then exporting its ARN as an Output.
CfnOutput takes the following parameters:
scope: The scope of the Output. In this case, we are using the current stack as the scope.id: The ID of the Output. This is used to uniquely identify the Output within the stack.value: The value of the Output. This can be a string, a number, or even a complex object.export_name: The name of the Output. This is used to uniquely identify the Output across stacks.
Viewing Outputs
Let’s modify our app.py file to view the outputs of our stack.
# app.py
import aws_cdk as cdk
from cdk_app.s3_stack import S3Stack
app = cdk.App()
S3Stack(app, "S3Stack")
app.synth()Now, run cdk deploy to deploy the stack. Once the stack is deployed, you will see the following output:
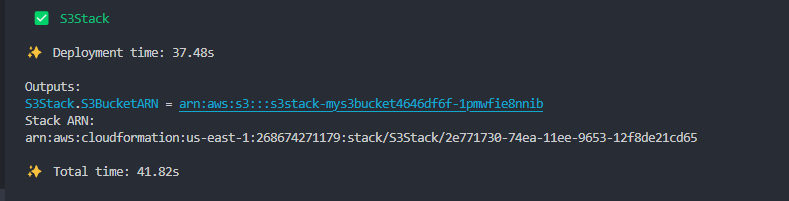
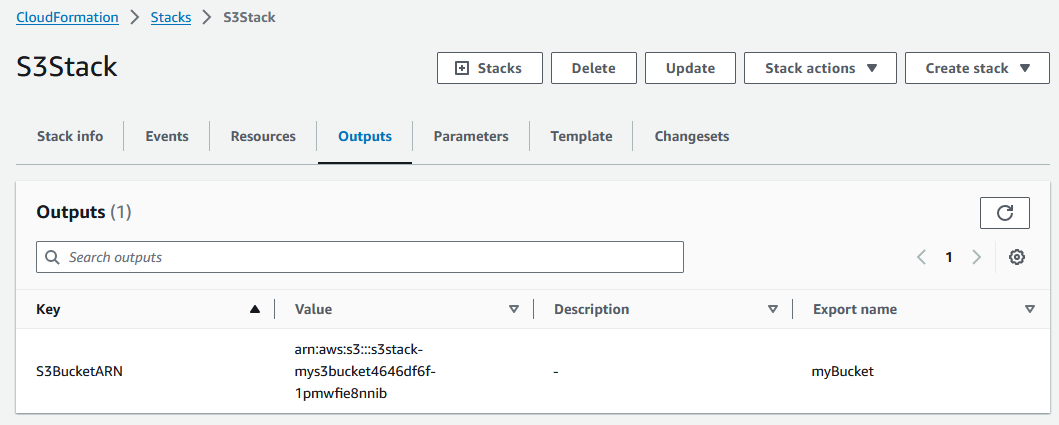
You can also view the outputs of a stack using the AWS Console. Go to the CloudFormation service and select your stack. Then, click on the Outputs tab. You will see the following:
What happens during to Output during cdk synth?
Let’s try printing the Output by modifying our cdk_app/s3_stack.py file:
# cdk_app/s3_stack.py
from aws_cdk import (
Stack,
aws_s3 as s3,
RemovalPolicy,
)
from aws_cdk import CfnOutput # 👈🏽 Import the CfnOutput class
from constructs import Construct
class S3Stack(Stack):
BUCKET_ID = "MyS3Bucket"
def __init__(self, scope: Construct, construct_id: str, **kwargs) -> None:
super().__init__(scope, construct_id, **kwargs)
myBucket = s3.Bucket(self, id=self.BUCKET_ID, removal_policy=RemovalPolicy.DESTROY)
# 👇🏽 Print the bucket ARN
print(myBucket.bucket_arn)
# 👇🏽 Output the bucket ARN
CfnOutput(self, id="S3BucketARN", value=myBucket.bucket_arn, export_name="MyS3BucketARN")Now run cdk synth, we get the following:

So what is this Token that is being printed? Token is a placeholder value that is replaced with the actual value by CloudFormation during deployment.
So, that means that the value of the Output is not known before deployments and cannot be accessed in our code. We can use a reference but CDK will not be able to resolve it during synth hence if you put in conditional logic based on the value of the Output, it will not work.
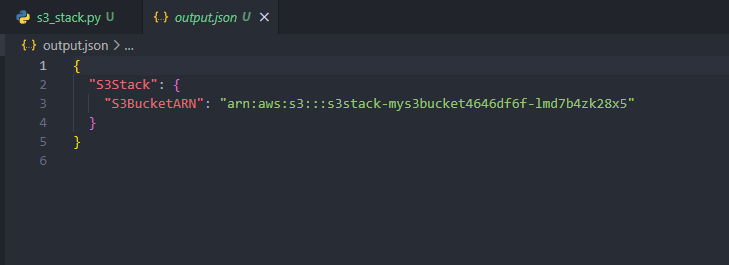
Print Output values to a file in CDK
Sometimes, you might want to print the values of the Outputs to a file. For example, you might want to print the values of the Outputs to a file and then use that file in your CI/CD pipeline.
To do add modify your deployment command as shown below:
cdk deploy <stack-name> --outputs-file ./output.jsonThis will print the values of the Outputs to a file called output.json in the current directory.
Need help?
Start a discussion on GitHub if you’ve got questions or improvements. Open discussions →